Projekt-Entstehung
Dieses Projekt wurde in enger Zusammenarbeit mit Google KI und Antigravity in einem 4-stufigen Konzept entwickelt, bei dem 3 spezialisierte Agenten eingesetzt wurden.
Die initiale Entwicklungszeit betrug lediglich ca. 1 Stunde! Die Entwicklung hat jedoch so viel Spaß gemacht, dass ich danach noch längere Zeit an Optimierungen und Erweiterungen (wie der Hall of Fame und dem Brain Viewer) gearbeitet habe.
Live Simulation (Video)
Klicke auf das Bild, um das Video der Simulation abzuspielen.

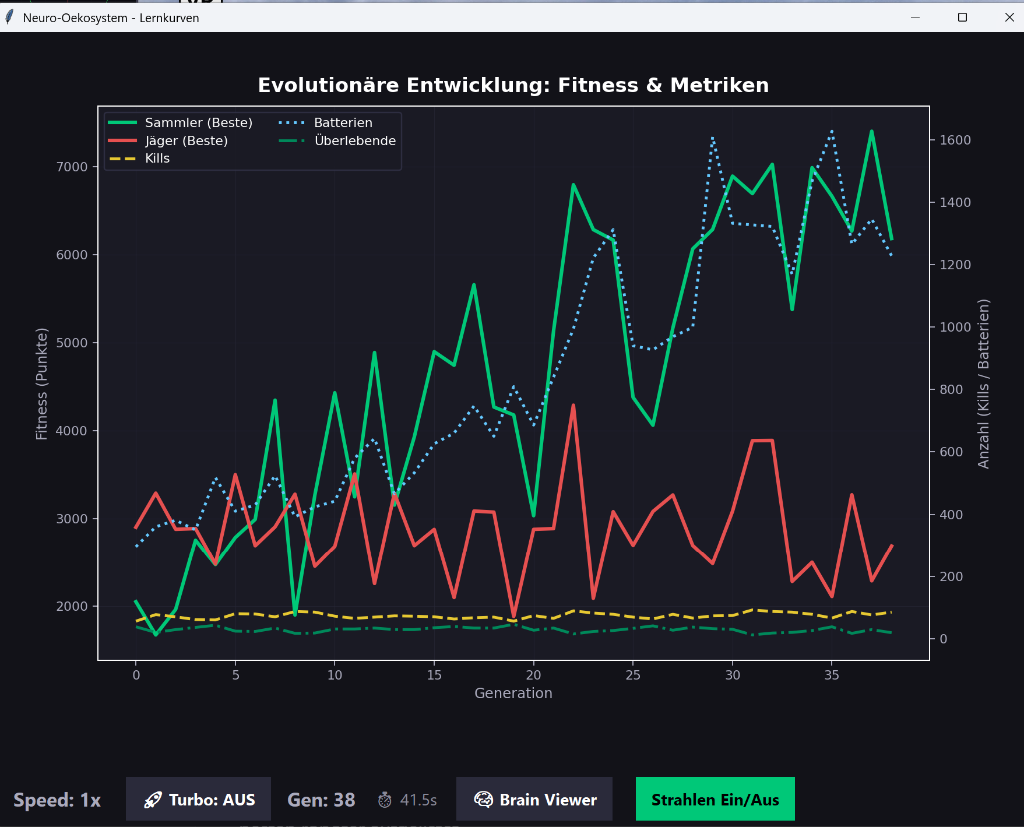
Evolution im Zeitraffer
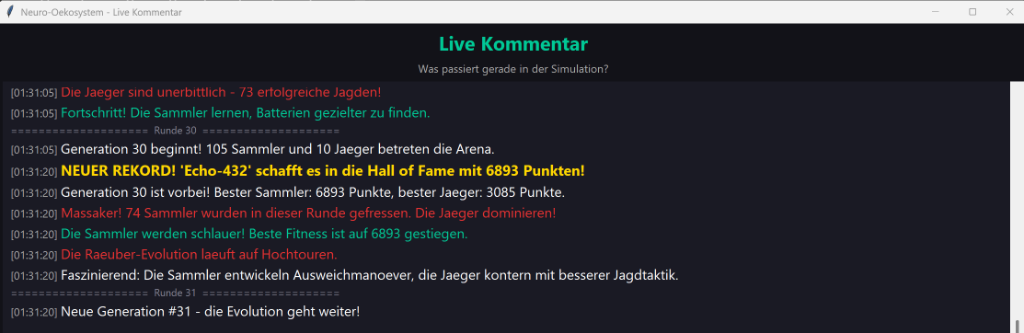
Was passiert, wenn man virtuelle Roboter in eine Welt setzt, ihnen ein neuronales Netz als Gehirn gibt und die Natur entscheiden lässt, wer überlebt? Genau das ist RoboterEvolution.
Die Akteure in diesem Ökosystem:
- Grüne Sammler (100): Müssen gelbe Batterien sammeln, um Energie zu tanken, und Jägern ausweichen.
- Rote Jäger (10): Müssen Sammler fangen, um zu überleben.
- Blaue Hall-of-Fame Gäste (5): Die besten Gehirne aller Zeiten, die live als Vorbilder mitspielen.
Beide Arten entwickeln ihre Strategien durch den NEAT-Algorithmus (NeuroEvolution of Augmenting Topologies) gleichzeitig weiter. Es entsteht ein evolutionäres Wettrüsten.
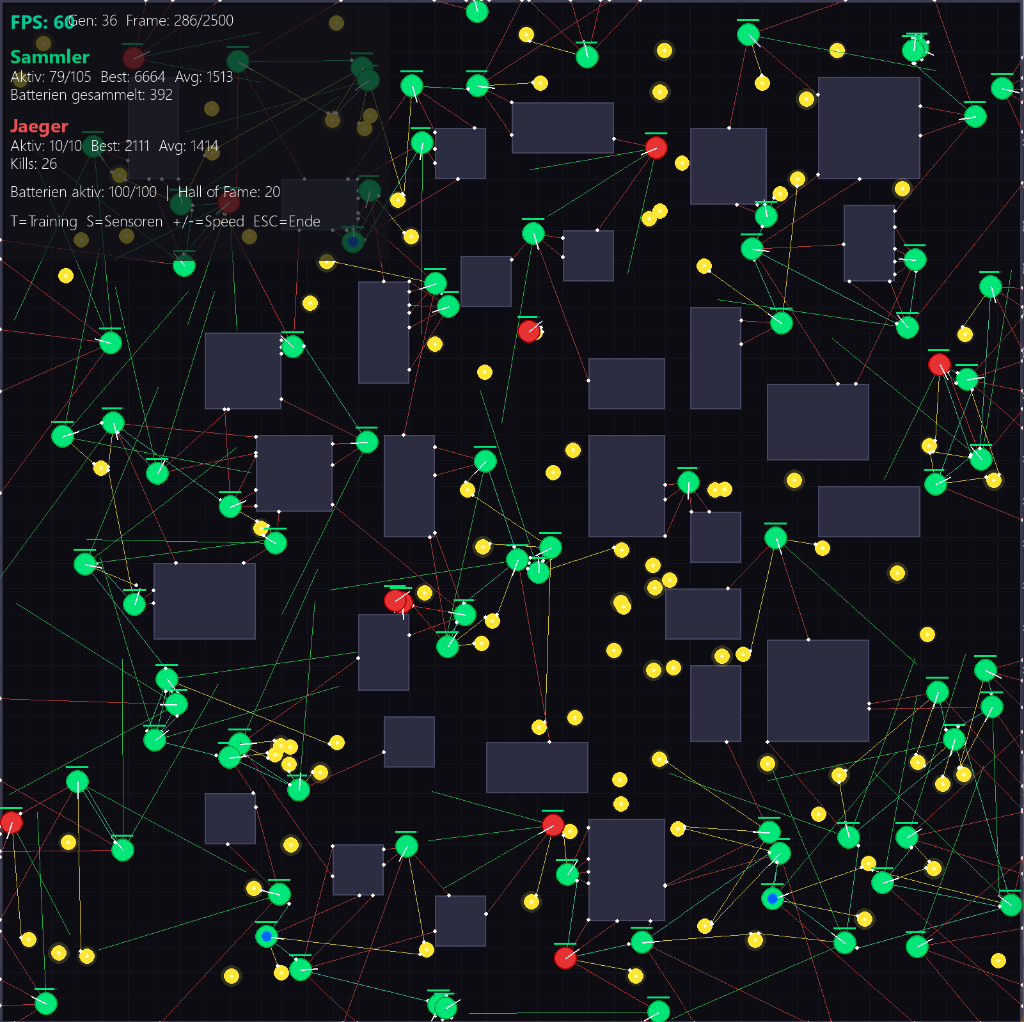
Wie lernen die Roboter? (Sichtfelder & Turbo)
Jeder Roboter besitzt mehrere Sichtstrahlen (Raycasting), ähnlich wie Radar. Ein wichtiger Erfolgsfaktor war die Umstellung auf diskrete Sensor-Signale: Für jeden Objekttyp (Wand, Batterie, Jäger) gibt es nun ein eigenes Signal (0 oder 1), anstatt alles in einer Zahl zu kodieren. Die neuronalen Netze lernen so viel schneller, diese Inputs in Motorbefehle (linker/rechter Motor) umzuwandeln.
Die Physik- und Sichtberechnungen sind sehr rechenintensiv. Daher ist ein Turbo-Mode implementiert. Dieser schaltet das grafische Rendering ab und nutzt alle Prozessorkerne aus, um Millionen von Berechnungen pro Sekunde durchzuführen und die Evolution massiv zu beschleunigen.
Das "Wärmer/Kälter"-System (Fitness-Gradient)
Ein entscheidender Durchbruch im Lernen der Roboter war die Einführung eines Proximity-Gradienten. Statt nur bei einem Event (Batterie berührt, gefressen) Feedback zu geben, erhalten die Roboter jeden Frame ein Richtungssignal: Ein kleiner Bonus, wenn sie sich einer Batterie nähern ("wärmer"), und eine Strafe, wenn ein Jäger in der Nähe ist. Ohne dieses kontinuierliche Feedback wäre das Lernen fast unmöglich!
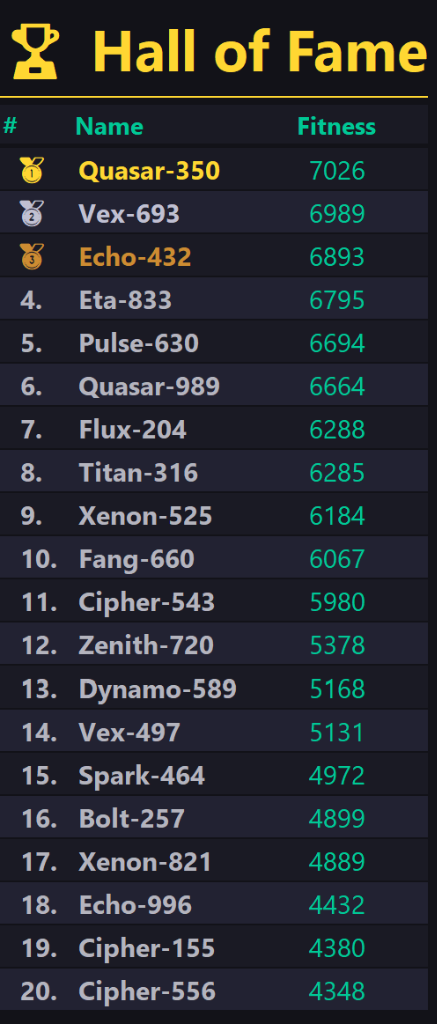
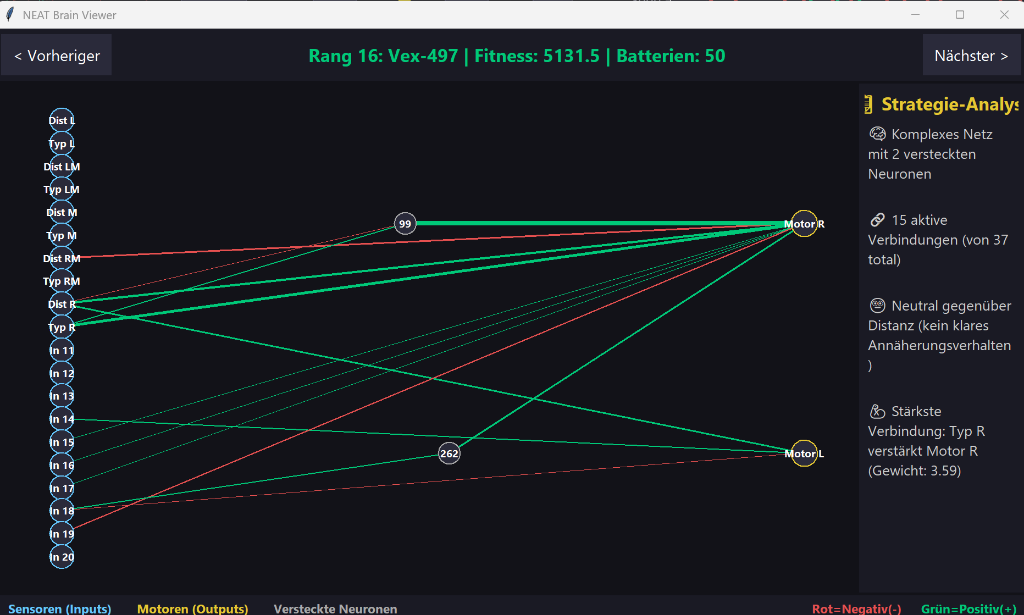
Hall of Fame & Brain Viewer
Die besten Roboter-Gehirne aller Generationen werden in der Hall of Fame verewigt. Interessant ist, dass diese Roboter völlig selbstständig lernen. Niemand hat ihnen gesagt, wie man ausweicht oder jagt.
Ein besonderes Highlight ist die Live-Injektion: In jeder Generation werden die besten 5 Roboter der Hall of Fame automatisch als unsterbliche, cyan-blaue "Gast-Roboter" ins laufende Spiel eingespeist, um der aktuellen Population als Vorbild zu dienen!
Mit dem Brain Viewer können wir sogar "in das Gehirn" der Roboter schauen. Auch wenn die Netze am Anfang noch klein sind (z.B. nach 42 Generationen), sieht man deutlich, wie Verbindungen zwischen Sensoren und Motoren gestärkt oder geschwächt werden.
System-Architektur
Die Software-Architektur dieses Projekts trennt UI, Simulation und KI-Logik sauber voneinander:
Fazit
Dieses Projekt ist anspruchsvoll, macht aber extrem viel Spaß. Es fühlt sich an wie ein Computerspiel, ist aber gleichzeitig hochgradig lehrreich. Es zeigt, wie mächtig Neuroevolution sein kann und wofür Simulationen im Bereich des maschinellen Lernens gut sind: Sie ermöglichen es uns, emergentes Verhalten und komplexe Strategiefindung in geschützten Räumen zu studieren.