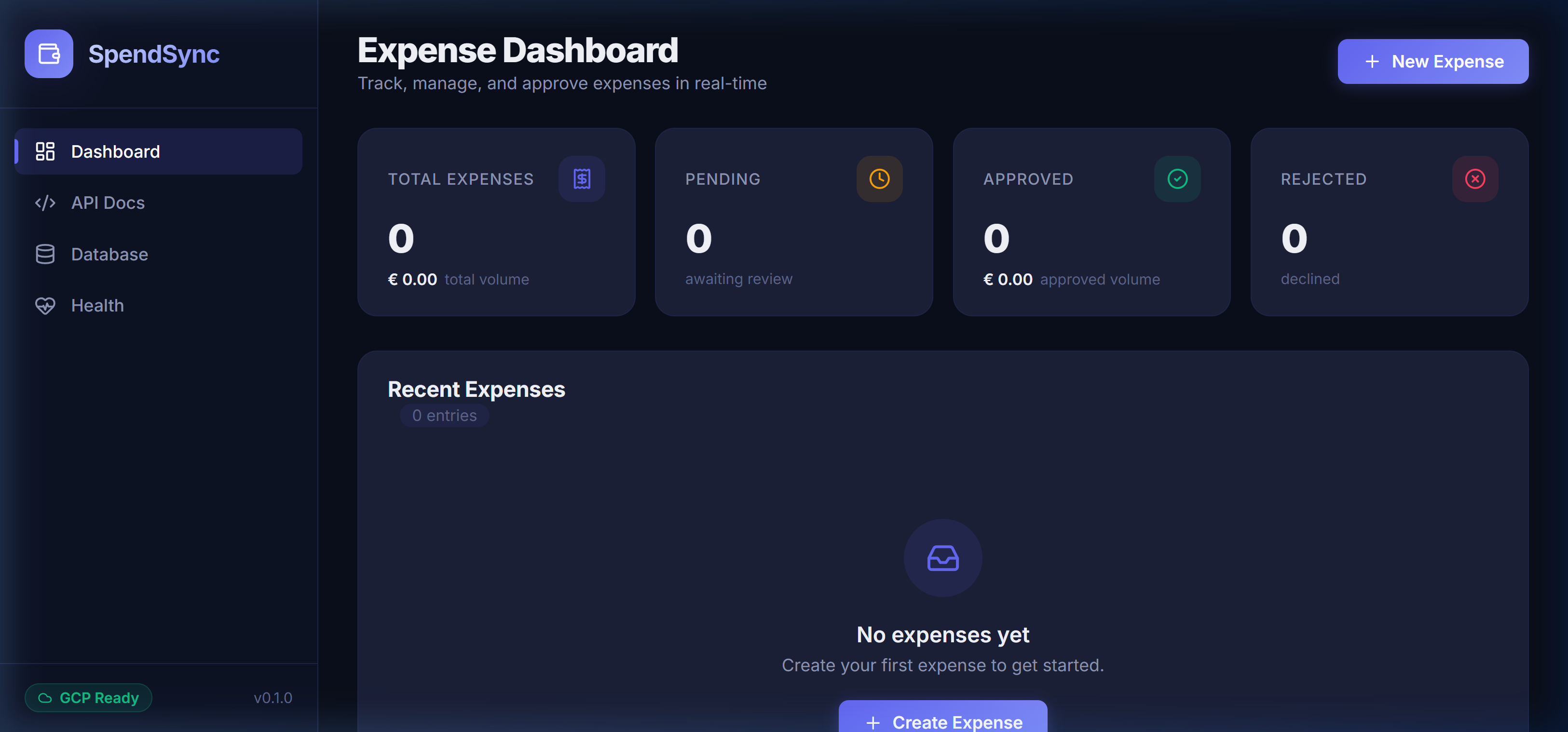
Es gibt Projekte, die zeigen, was möglich ist, wenn man sich traut, Neuland zu betreten. SpendSync Cloud ist genau so ein Projekt. Ich hatte buchstäblich null Erfahrung mit Docker und null Erfahrung mit Google Cloud Platform. Keine Tutorials vorher durchgearbeitet, keine Kurse besucht, kein Sandbox-Projekt vorab getestet. Einfach losgelegt – mit einer AI an meiner Seite.
Das Ergebnis? Eine produktionsreife, cloud-native Webanwendung mit REST API, interaktivem Dashboard, Swagger-Dokumentation, Docker Multi-Stage Build und Live-Deployment auf Google Cloud Run. Die ganze Geschichte vom ersten docker build bis zur öffentlich erreichbaren URL – in unter 2 Stunden. Und das Beste: Alles komplett mit AI erstellt.
100% AI-Powered Development
Dieses gesamte Projekt – vom Spring Boot Backend über das Dockerfile bis zum Google Cloud Deployment – wurde vollständig mit KI-Unterstützung entwickelt. Kein Copy-Paste aus Stack Overflow, keine stundenlange Doku-Recherche. Ich habe dem AI-Agenten meine Vision beschrieben und er hat sie Schritt für Schritt umgesetzt. Mein Beitrag: Architektur-Entscheidungen treffen, Qualität prüfen, Richtung vorgeben. Die Maschine hat den Rest erledigt.
Was ist SpendSync?
SpendSync ist eine cloud-native Expense Tracking Webanwendung – ein modernes System zur Erfassung und Verwaltung von Ausgaben und Spesen. Es ist bewusst als Portfolio-Referenzprojekt konzipiert, das Enterprise-Architektur und Cloud-Deployment Best Practices demonstriert.
Ausgaben erfassen
Beschreibung, Betrag, Datum und Status
Echtzeit-Dashboard
KPI-Cards mit Total, Pending, Approved, Rejected
REST API
Mit interaktiver Swagger-Dokumentation
Cloud-Deployment
Auf Google Cloud Run als Docker Container
Enterprise-Architektur: 3-Tier mit Spring Boot 3
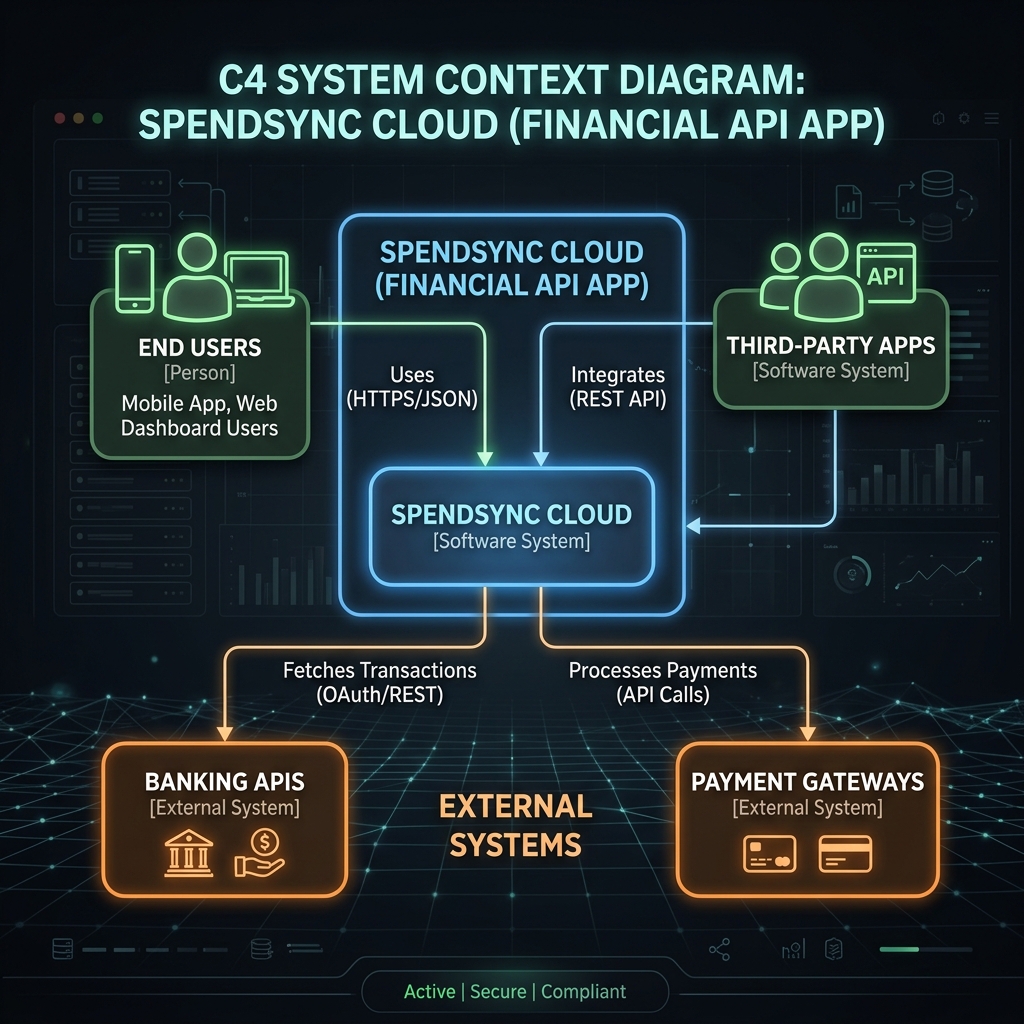
Die Architektur folgt dem bewährten 3-Tier Enterprise-Pattern – ein Prinzip, das ich aus meiner langjährigen Backend-Entwicklung kenne. Jede Schicht hat eine klar definierte Verantwortung, und der Wechsel der Datenbank von H2 auf PostgreSQL erfordert null Code-Änderungen – nur Konfiguration:
Presentation ? ExpenseController (REST/JSON) + DashboardController (MVC/Thymeleaf)
?
Business ? ExpenseService (Geschäftslogik, Validierung, Aggregation)
?
Data Access ? ExpenseRepository (Spring Data JPA ? H2 / Cloud SQL)
?
Database ? H2 In-Memory (Dev) | PostgreSQL/Cloud SQL (Prod)Die Separation of Concerns ist sauber umgesetzt: Getrennte Controller für REST (@RestController) und MVC (@Controller), die sich einen gemeinsamen Service teilen. UUID als Primary Key für globale Eindeutigkeit in verteilten Systemen, BigDecimal für Geldbeträge (weil 0.1 + 0.2 ? 0.3 bei Double), und Enum als STRING gespeichert für Vorwärtskompatibilität.
Docker: Mein erster Container – und gleich richtig
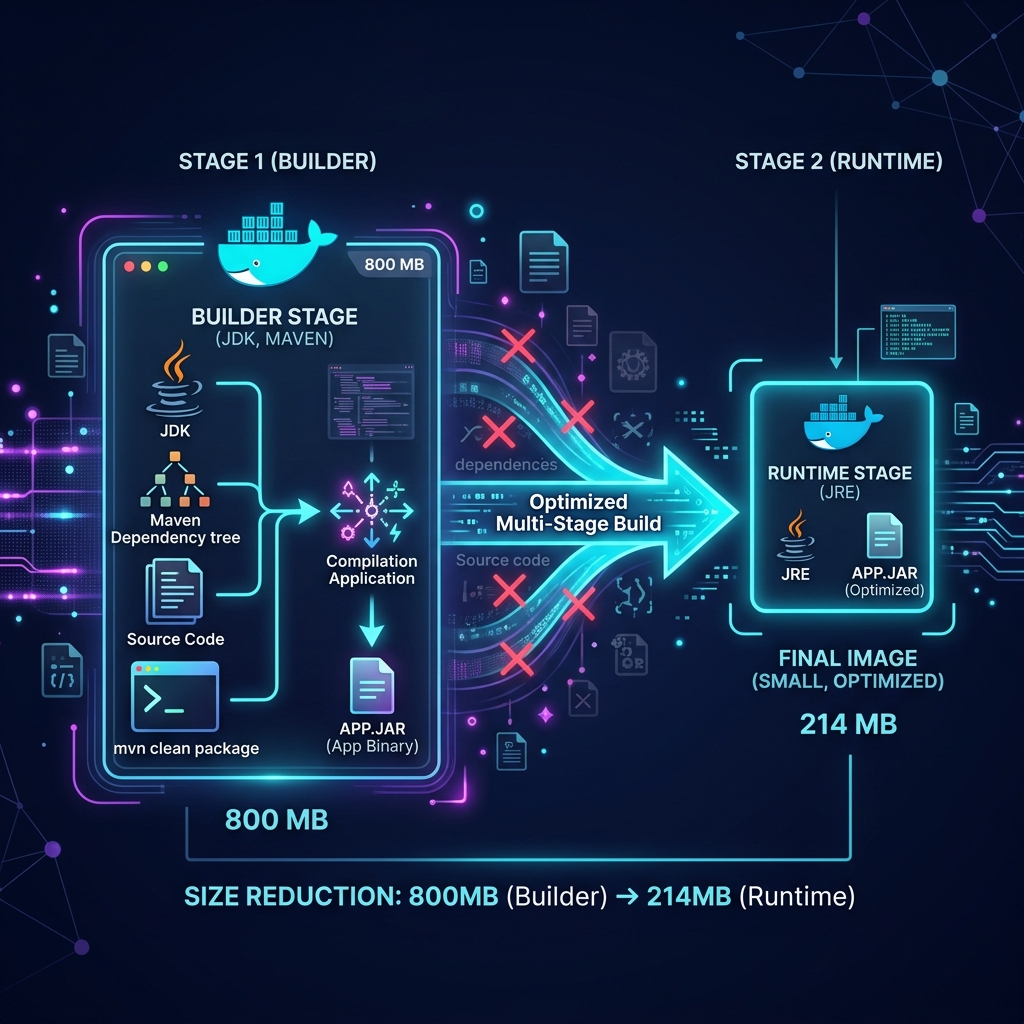
Bevor ich dieses Projekt gestartet habe, wusste ich über Docker genau so viel wie der durchschnittliche Developer, der es „irgendwann mal lernen wollte": Quasi nichts. Kein docker build je ausgeführt, kein Dockerfile je geschrieben, kein Container je deployed. Und trotzdem ist das Resultat kein Quick-and-Dirty-Hack, sondern ein produktionsoptimierter Multi-Stage Build:
# -------------------------------------------
# STAGE 1: Builder (wird nach Build verworfen)
# -------------------------------------------
FROM eclipse-temurin:21-jdk AS builder
WORKDIR /app
# Dependencies zuerst ? Docker Layer Caching
COPY pom.xml ./
RUN mvn dependency:resolve -B
COPY src ./src
RUN mvn package -DskipTests -B
# -------------------------------------------
# STAGE 2: Runtime (finales Image: ~214 MB)
# -------------------------------------------
FROM eclipse-temurin:21-jre
RUN groupadd --system appgroup && \
useradd --system --gid appgroup appuser
COPY --from=builder /app/target/*.jar app.jar
USER appuser
ENTRYPOINT ["java", "-jar", "app.jar"]Ohne Multi-Stage
JDK + Maven + Build-Tools
Mit Multi-Stage
Nur JRE + App JAR
Kleiner
Schnellerer Cold Start
Die Security Best Practices sind ebenfalls direkt implementiert: Die Anwendung läuft als Non-Root User (appuser), nicht als root. Das JRE-Image enthält keinen Compiler – minimale Angriffsfläche. Und das Docker Layer Caching ist optimiert: pom.xml wird vor dem Source Code kopiert, sodass Dependencies gecacht werden und nur Code-Änderungen einen Rebuild auslösen.
Google Cloud Run: Serverless Container Deployment
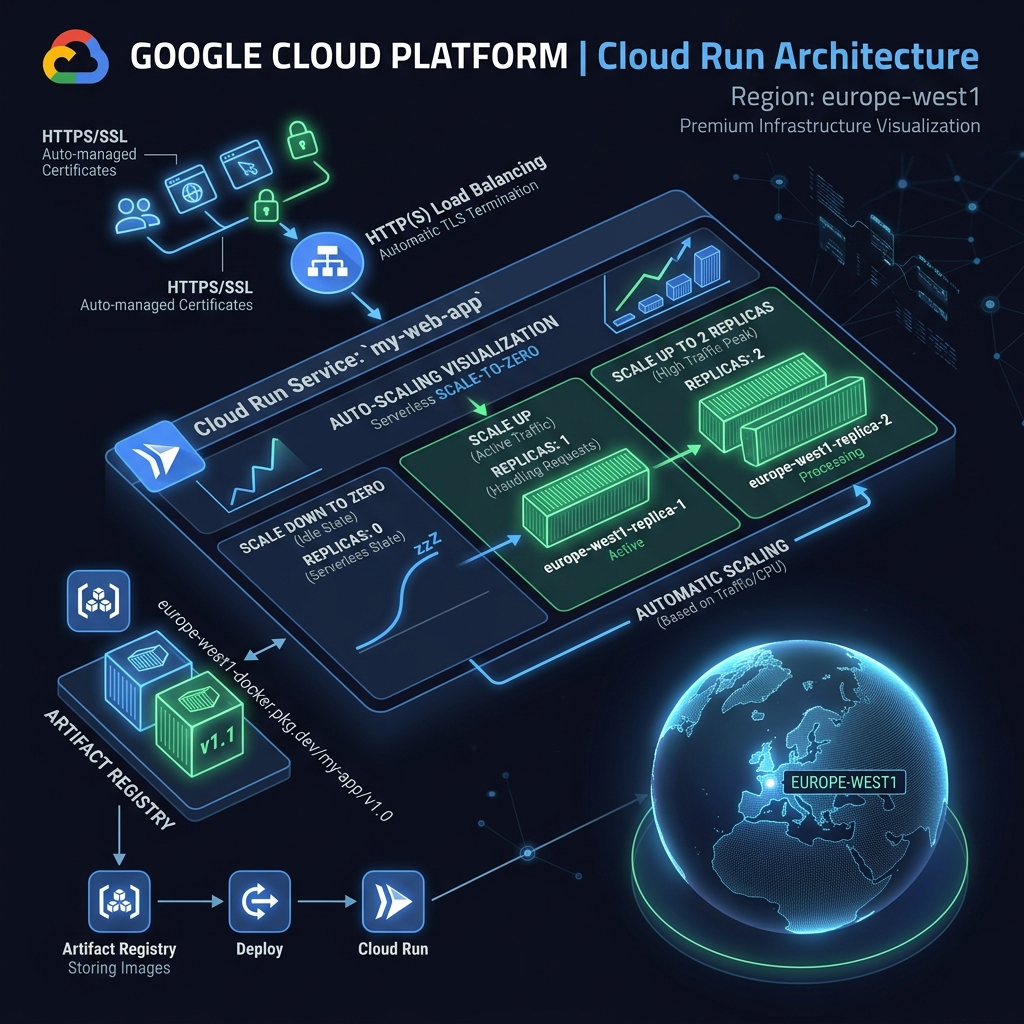
Der nächste Schritt nach dem Docker-Build: Ab in die Cloud. Auch hier: Null Vorwissen. Ich hatte vorher nie mit Google Cloud gearbeitet, keine Projekte angelegt, keine CLI-Tools konfiguriert. Die AI hat mich durch den gesamten Prozess geführt – vom gcloud auth login bis zum finalen gcloud run deploy:
# Docker Image für Google Cloud taggen
$ docker tag spendsync-cloud-gcp:0.1.0 \
europe-west1-docker.pkg.dev/spendsync-cloud/spendsync-repo/spendsync-cloud-gcp:0.1.0
# Image in Google Artifact Registry pushen
$ docker push europe-west1-docker.pkg.dev/.../spendsync-cloud-gcp:0.1.0
# Cloud Run Deployment – eine Zeile, global erreichbar
$ gcloud run deploy spendsync \
--image=europe-west1-docker.pkg.dev/.../spendsync-cloud-gcp:0.1.0 \
--region=europe-west1 \
--memory=512Mi \
--min-instances=0 \
--max-instances=2
? Service deployed: https://spendsync-714987230781.europe-west1.run.appRegion: europe-west1
Belgien – nächstes Rechenzentrum für DACH
Auto-Scaling: 0 ? 2
Scale-to-Zero = $0 Kosten im Leerlauf
HTTPS: Auto-Managed
Google-managed SSL/TLS-Zertifikat
Das Geniale an Cloud Run: Scale-to-Zero. Kein Traffic? Null Instanzen. Null Kosten. Kommt ein Request? Innerhalb von ~2 Sekunden ist eine Instanz hochgefahren. Bei hoher Last skaliert der Service automatisch auf bis zu 2 Instanzen. Und das Ganze kostet für ein Portfolio-Projekt praktisch $0.00 pro Monat – alles im Free Tier.
Technologie-Stack im Überblick

Kompletter Technologie-Stack
Alle Technologien, die in SpendSync Cloud zum Einsatz kommen:
Backend & Framework
- Java 21 (LTS)
- Spring Boot 3.4.4
- Maven Build Tool
- Lombok (Boilerplate-Reduktion)
Persistenz & API
- Spring Data JPA / Hibernate
- H2 In-Memory (Dev)
- SpringDoc OpenAPI 2.8.6
- Jakarta Bean Validation
Frontend & Monitoring
- Thymeleaf Template Engine
- Premium Dark-Mode CSS
- Spring Actuator (Health)
- GCP Cloud Monitoring
DevOps & Cloud
- Docker Multi-Stage Build
- Google Cloud Run
- Google Artifact Registry
- Non-Root Container Security
Premium Dashboard: Dark-Mode mit Glassmorphism
Das Web Dashboard wird serverseitig mit Thymeleaf gerendert – kein separates Frontend-Deployment nötig. Die gesamte Anwendung (API + Dashboard) läuft in einem einzigen Spring Boot Container. Das Design folgt einem Premium Dark-Mode Konzept mit Glassmorphism-Effekten, responsivem Layout und Micro-Animations:
4 KPI-Statistik-Cards
Total Expenses, Pending, Approved, Rejected – mit Echtzeitberechnung der Volumina.
Expense-Tabelle
Sortierte Liste aller Ausgaben mit Status-Badges, UUID-Anzeige und Sidebar-Navigation.
Erstell-Modal & POST-Redirect-GET
Formulare mit PRG-Pattern – keine doppelten Einträge bei F5/Refresh möglich.
2 Stunden: Von der Idee bis zum globalen Deployment

Lass mich das in klare Worte fassen, denn ich glaube, das ist der Teil, der am meisten beeindruckt:
Docker-Erfahrung
Nie vorher ein Dockerfile geschrieben
GCP-Erfahrung
Nie vorher Google Cloud benutzt
Gesamtzeit
Von Null bis Live-Deployment
Ich hatte kein Vorwissen zu Docker. Ich hatte kein Vorwissen zu Google Cloud. Und trotzdem steht nach gerade mal 2 Stunden eine produktionsreife Anwendung live im Netz – mit Multi-Stage Docker Build, Non-Root Security, JVM-Containeroptimierung, Google Artifact Registry, Cloud Run Auto-Scaling und automatischem SSL/TLS.
Wie ist das möglich? Weil KI-gestützte Entwicklung nicht bedeutet, dass man die Maschine blind Code generieren lässt. Es bedeutet, dass man seine langjährige Systemerfahrung als Kompass nutzt, während die AI die Implementierungsdetails übernimmt. Ich weiß, was eine gute Architektur ausmacht. Ich weiß, warum Non-Root Container wichtig sind. Ich weiß, warum BigDecimal statt Double. Die AI weiß, wie man das Dockerfile schreibt und welche gcloud-Befehle man braucht. Zusammen sind wir in der Implementierung unschlagbar schnell (Testzeiten sind natürlich noch zu berücksichtigen).
Mein Fazit
Früher hätte ich für Docker und Google Cloud erstmal einen Udemy-Kurs gekauft, 20 Stunden Tutorials geschaut, ein Sandbox-Projekt gebaut und dann vielleicht nach 2 Wochen mein erstes Deployment gemacht. Heute mache ich das in 2 Stunden – und das Ergebnis ist besser, weil die AI Best Practices kennt, die in keinem Tutorial stehen. Das ist nicht Faulheit. Das ist die Zukunft der Softwareentwicklung. Und es macht verdammt viel Spaß.
Enterprise-Entscheidungen: Warum so und nicht anders
Dependencies sind immutable (final), explizit deklariert und testbar. Spring-offizielle Empfehlung.
Verhindert das Anti-Pattern, klare Transaktionsgrenzen, keine N+1 Query Probleme.
@RestController für JSON, @Controller für HTML – gleicher Service, keine Logik-Duplizierung.
min-instances=0 – Portfolio-Projekt mit ~$0/Monat statt Always-On Kosten.
-XX:+UseContainerSupport, 75% RAM als Heap, Non-blocking Entropy für schnelleren Start.
Zentraler GlobalExceptionHandler – Security Best Practice, keine internen Details nach außen.
Fazit: Cloud-Native ist kein Hexenwerk – mit dem richtigen Werkzeug
SpendSync Cloud beweist, dass die Kombination aus Architekturverständnis und KI-gestützter Entwicklung traditionelle Skill-Barrieren pulverisiert. Docker? Gelernt. Google Cloud? Gemeistert. Multi-Stage Build, Artifact Registry, Cloud Run, Auto-Scaling, SSL/TLS – alles in einer einzigen Session. Nicht als oberflächliches Hello-World, sondern als produktionsnahes Proof-of-Concept mit Enterprise-Architektur. Dieses Projekt demonstriert AI-gestütztes Cloud-Deployment, wohingegen die finale Absicherung von Security-Edge-Cases für das Manuelle Architekten-Review vorgesehen ist.
Das Projekt zeigt, was moderne Entwickler ausmacht: Nicht der, der jede Technologie schon mal benutzt hat – sondern der, der jede neue Technologie in Rekordzeit meistern kann. Weil Erfahrung, Mustererkennung und die richtigen Werkzeuge zusammenkommen. Docker und Google Cloud standen nicht auf meinem Lebenslauf. Jetzt stehen sie dort – mit einem live deployen Beweis.
Hinweis zum Live-Status
Die SpendSync-Instanz auf Google Cloud Run ist aktuell möglicherweise deaktiviert (öffentlicher Zugang entfernt), um Cloud-Kosten zu minimieren. Das Dashboard und der Screenshot oben zeigen die Anwendung im aktiven Zustand. Bei Interesse kann ich die Instanz jederzeit wieder aktivieren – ein einziger gcloud-Befehl genügt.